Communication vendors are waking up to the need to invest in ML/AI in media processing. The challenge will be to get ML in WebRTC.
Two years ago, I published along with Chad Hart a report called AI in RTC. In it, we’ve reviewed the various areas where machine learning is relevant when it comes to real time communications. We’ve interviewed vendors to understand what they’re doing and looked at the available research.
We mapped 4 areas:
- Speech Analytics
- Voicebots
- Computer Vision
- RTC Quality and Cost Optimization
That last area was tricky. Almost everyone was using rule engines and heuristics at the time for all of their media processing algorithms and only a few made attempts to use machine learning.
My argument was this:
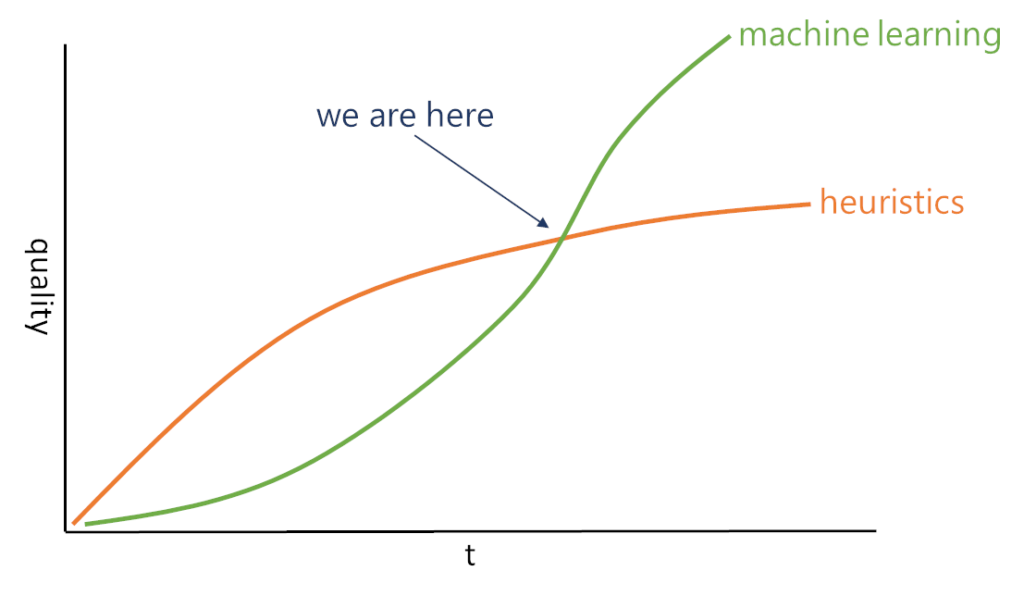
There’s so much we can do with rule engines and heuristics. Over time, machine learning will catch up and be better. We are now at that inflection point. Partially because of the technology advances, but a lot because of the pandemic.
ML in media processing is challenging
When looking at machine learning in media processing, there’s one word that comes to mind: challenging

Machine learning is challenging.
Media processing is challenging.
Together?
These are two separate and far apart disciplines that need to be handled.
The data you look at is analog in its nature, and there’s often little to no labeled data sets to work with.
A few of the things you need to figure out here?
- How do you find machine learning engineers, or whatever they are called in their titles this day of the week?
- Do these engineers know anything about media processing? How do you get them up to speed with this technology? Or is it the other way around? Getting media engineers trained in machine learning
- Can you generate or get access to a suitable data set to use? Do you even have access to enough data?
- Where do you focus your efforts? Audio or video? Maybe just network? Should you go for server side implementation or client side one? What about model optimizations?
- When do you deem your efforts fruitful? Ready for production?
This isn’t just another checkmark to place in your roadmap’s feature list. There’s a lot of planning, management effort and research that needs to go into it. A lot more than in most other features you’ve got lined up.
The noise suppression gold rush

If I had to pick areas where machine learning is finding a home in communications, it will be two main areas:
- Video background processing (more on that at some future point in time)
- Noise suppression
Both topics were always there, but took centerstage during the pandemic. People started working from weird places (like home with kids) and you now can’t blame them. One of the best games I play in workshops now? Checking who’s got the most interesting room behind him…
Video background is about stopping me from playing. Noise suppression is about you not hearing the lawn mower buzzing 16 floors below me, or the all-too-active neighbor above me who likes to home renovate whenever I am on a call – with a power drill.

This need has led to a few quick wins all around. The interesting 3 taking place in the domain of WebRTC (or near enough) are probably the stories about Google Meet, Discord/Krisp and Cisco/BabbleLabs.
Google Meet

In June, Serge Lachapelle, G Suite Director of Product Management was “called to the flag” and was asked to do a quick interview for VentureBeat on Google Meet’s noise suppression. Serge was once the product manager for WebRTC at Google and moved on to Google Meet a few years back.
You can watch the short interview here:
The gist of it?
- Google decided to implement it in the cloud
- They use “secure” TPUs for that (Tensorflow Processing Units, a specialized chip in the Google Cloud for machine learning workloads)
- The feature is optional. It can be enabled or disabled by the user
- Noises it cancels are almost arbitrary. It is something that is really hard to define as initial requirements. It is also something that will be fine tuned and tweaked over time by Google
As I stated earlier, Google isn’t taking any prisoners here and contributing this back to the community freely as part of WebRTC. They are making sure to differentiate by making sure their machine learning chops are implemented outside of the open source WebRTC library. This is exactly what I’d do in their place.
Discord

Krisp is one of the few vendors tackling machine learning in media processing and doing that as a product/service and not a feature. They’ve been at it for a couple of years now, and things seems to be going in their favor this year.
Krisp managed to do a few things:
- Focus on noise suppression. They started “all over the place” with voice related media algorithms, and seem to be finding product-market-fit in noise suppression
- Won a deal/partnership with Discord
- Got their technology to work inside the browser (see here)
Execution
The Discord story was first published in April on Discord’s blog. Noise suppression was added in beta to the Discord desktop app. Was that done using the browser technology used in Discord’s Electron app or by the native implementation that Krisp has is an open question, but not the most relevant one.
Three months later, in July, Discord got noise suppression into iOS and Android. This was also done using Krisp and with a spanking short video explainer:

Ongoing success
Here are my thoughts here:
- Adding this to mobile means they got positive feedback on the desktop integration
- Especially considering how they phrased it:
As we continue to improve voice chat, Krisp is an integral part of making Discord your place to talk. No matter how stressful the world around us may be, Krisp is here to help every one of our 100 million monthly active users feel more connected to our far-away friends.
- 100M MAU is what Discord now has, and this is a vote of confidence in Krisp and in ML-based noise suppression technology
- Discord shouts to the world that they are using Krisp. Something not many companies do for their suppliers
- This may mean that they got this on the cheap (or free)
- Or it means that they are cozying up to Krisp
My read of it? Krisp might be acquired and gobbled up by Discord to make sure this technology stays off the hands of others – if that hasn’t happened already – just look at this page – https://krisp.ai/discord/ (and then compare it to their homepage).
Cisco

In the case of Cisco, the traditional approach of reducing risk by acquiring the technology was selected – acquihiring.
Last week, Cisco issued a press release of their intent to acquire BabbleLabs.
BabbleLabs was in the same space as Krisp. A company offering machine learning-based algorithms to process voice. The main algorithm there today as we’ve seen is noise suppression. This is what Cisco were looking for and now they will have it inhouse and directly integrated into WebEx.
Cisco devices not to self-develop. They also decided to own the technology. The reasons?
- Google owns it
- Zoom has its own implementation
- That left… WebEx
Will BabbleLabs stay open? No.
In his recent post about the acquisition, Chris Rowen, CEO of BabbleLabs, explains what lead to the acquisition and paints a colorful future. The only thing missing in that post is what about existing customers. The answer is going to be a simple one: They will be supported until the next renewal date, when they will simply be let go.
A win to Krisp. If it isn’t in the process of being acquired itself already.
Who’s next?

This definitely isn’t the end of it. We will see more vendors taking notice to this one and adding noise suppression. This will happen either through self-development or through the licensing of third party solutions such as Krisp.
The challenge with these third party solutions is that they feel more like a feature than a product or a full fledged service. On one hand, everyone needs them now. On the other hand, they need to be embedded deep in the technology stack of the vendors using them. The end result is relatively small companies with a low ceiling to their potential growth (=not billion dollar companies). This puts a strain on such companies, especially if they are VC backed.
On the other hand, everyone needs noise suppression now. Where do they go to buy it? How do they build it?
Noise suppression is just the beginning

Noise suppression is just the beginning here. In the workshop I did last month on WebRTC innovation and differentiation, I’ve taken the time to focus on this. How machine learning is now finding a place in bringing differentiation to the actual communication. Noise suppression was one of the topics discussed, with many others.
There were 3 main areas that we will see growing investment in:
- Voice treatment – noise suppression, packet loss concealment, voice separation, etc
- Video treatment – video compression, super resolution, etc
- Background blur/replacement – I am placing it on its own, as it seems to be the next big thing
Each of these domains has its own set of headaches and nuances.
There’s also voice compression – Microsoft Satin and Google Lyra are AI-powered voice codecs recently announced.
Server, native or browser?

This is a big question.
If you look at the examples I’ve given for noise suppression:
- Google Meet chose cloud
- Discord is native and browser
- WebEx is native as far as I can tell
Going for native or browser means you’re closer to the edge and the user. You can do things faster, more efficiently and with a lower cost to you (you’re practically employing the user’s device to bear the brunt of running the machine learning inference algorithm). That also means you have less resources for other things like the actual video and you’re limited in the size of the model you can use for your algorithm.
Cloud means a central place where you can do training, inference, A/B testing, etc. It is probably easier to maintain and operate in the longer run, but it will add some delay to the media and will definitely cost you to run at scale.
Each company will choose differently here, and you may see a company choosing for one algorithm to run it in the cloud and for another to run on the edge.
Are you planning for this ML/AI future?

Machine learning and artificial intelligence is in our future. Both in the communication space and elsewhere. It is finally coming also to media processing directly. In a few years, it will be a common requirement from services.
Are you planning for that in any way?
Do you know how you’re going to get there?
Will you be relying on third parties or on your own inhouse technology for it?
There are no open source solutions at the moment for any of it. At least not in a way that can be productized in a short timeframe.
If you need assistance with answering these questions, then check my workshop. It is recorded and available online and it is more relevant than ever.
WORKSHOP: WebRTC Innovation and Differentiation in a Post Pandemic World
Thank you for the post! Quite exciting it looks this future!
You really should at nVidia’s RTX Voice to your list. It’s every bit as good as those you mention, maybe better. It requires an nVidia RTX GPU. However, there’s a very simple want to lift the hardware constraint to it can work on older GTX cards, too.
Finally, I would be remiss if I did not say that all these things are not equivalent of choosing and using the right hardware. A headset with a boom-mounted, noise cancelling microphone avoids the noise that all these highly technical things attempt to remove after-the-fact.
Not only nVidia… I was told I also missed Microsoft, and I also forgot about Amazon in this domain.
A better headset is better than any algorithm, which is why it is becoming so hard to purchase good headsets now (they are almost all always out of stock since the pandemic started). The thing is you don’t always have access to a good headset.
Hi, nice post!
So, what about noiseSuppression in navigator.mediaDevices.getUserMedia ? Is it improving? Seems it is not working
First it needs to be implemented by the browser.
Then it needs to be implemented by your microphone/speaker – the intent at least is for this parameter to be passed along with the hardware peripherals and if they support it then enable it on their end.
You should have probably mentioned Microsoft Deep Noise Suppression Challenge https://dns-challenge.azurewebsites.net/Interspeech2020, which was won by Amazon.
They have another one going on right now.
what is javascript code for noise suppression, so that only voice should come in webcam
What a great piece Tsahi, only just read it (a bit late to the party). I think with the fragmentation/modularisation we’re expected to see in WebRTC over the next year, it’s really becoming more and more practical to do this stuff in the browser, but I think some features will always be better in the cloud, and some features will always be better in the browser, for the reasons you said. I think from an engineering point of view we can do a lot of these features today, I think there’s customers/markets that desire them, the biggest question mark is can you make a business model that works. I think the fragmentation of WebRTC if it happens will help a lot to help with plug and play modules on the browser side, but on the cloud side it’s so deep in the technology stack cracking the business model is half the fun. It does look like Krisp will likely be acquired, I’m almost heart broken if that happens since I was hoping they could expand and offer the capability to more and more people, prove it can be done, but likely Discord wouldn’t want that. Maybe one way to make it more viable as a standalone entity is to offer multiple independent capabilities as a technology provider. Not just noise suppression, but many more, maybe then the numbers will look big enough to justify building a longer standing entity servicing this market. As you’ve pointed out there’s a lot of excited ML powered signal processing opportunities up for grabs.
Yes. My fear is also that the viability of vendors in this space is limited.