There are new audio codecs in town: Google Lyra and Microsoft Satin. Both banking on AI-based voice coding, and both will be fighting for inclusion in WebRTC.

Right on the heels of the changes we see in video codecs in WebRTC, with AV1 coming into the stage, and HEVC making an entrance in Apple devices, we now have a similar (?) story with voice codecs. Microsoft announced its AI-powered voice codec Satin in February. A week later, Google reciprocated in kind, announcing its low bitrate codec for speech compression Lyra.
Why now? What are the similarities and differences between these codecs? Where are they headed? And what does that mean to WebRTC and to you?
Table of contents
Audio codecs in WebRTC
It makes sense to start this by explaining a bit about audio codecs in WebRTC.
WebRTC has mandatory to implement codecs. For audio/voice, these codecs are G.711 and Opus.
For all intent and purposes G.711 is there as a legacy codec, to deal with narrowband audio. The result of which is low quality, unresilient audio. Using G.711 is mostly reserved to connect it with the telephony networks, and even there, I wouldn’t recommend it as a solution.
Opus is the main voice codec in WebRTC. It offers a highly flexible solution capable of handling anything from narrowband to fullband stereo and at low bitrates. You can read more in this article I’ve written years ago: The Rise of Opus to HD Voice Domination.
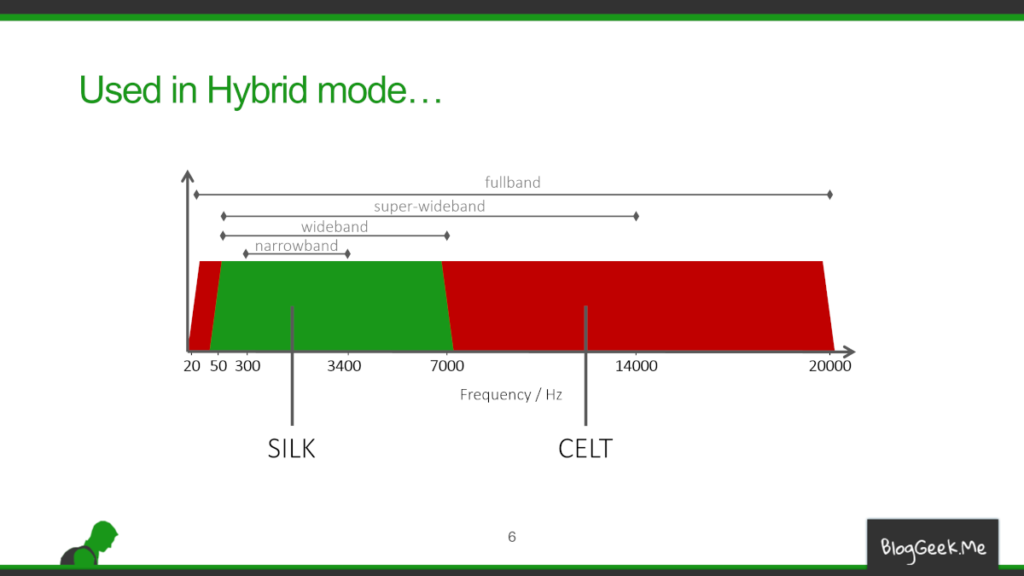
Opus is almost 10 years old. It has been created by meshing two separate codecs: SILK (for speech) and CELT (for music). The pandemic of 2020, and the increased reliance on virtual meetings has started to show its age and its limitations. Opus is a great codec, but these days, we can probably do better.
The two extremes in audio codecs: Low bitrate vs lossless
So what are the missing pieces? The things that Opus can’t get done on its own? There are two such areas that are actively being explored, and they are two extremes: highest possible audio quality and lowest possible bitrate.
Highest possible quality: Lossless audio coding
One extreme (unrelated to Lyra and Satin), is the strive for the highest possible audio quality. Getting there requires the use of lossless audio coding.
For all intent and purpose, what we do in VoIP today, and by extension in WebRTC, is use lossy coding. This means that we compress the audio and video in ways that don’t really allow us to reconstruct the original audio or video accurately, but instead it gets us “close enough” to there. It does that by trying to “get rid” only of information that we humans can’t discern – things the human eye and human ear would miss anyways.
As a crude example, I never did hear the difference between vinyl, cassettes and CDs – at least not enough for it to matter for me. On the other hand, I had a friend who complained that CDs don’t have the audio quality of vinyl records.
The most known lossless audio codec is FLAC. It has nothing to do with WebRTC. Yet.

Lowest possible bitrate: AI based compression
In the other end of this spectrum lies the lowest possible bitrate we can comfortably reach.
It turns out that Opus is good, but not great.
At a time where bandwidths are increasing, why do we even discuss getting voice codecs into lower and lower bitrates? What would be the incentive?
These questions are doubly important considering the fact that we’re heading towards a remote video filled world. And we know that video takes up considerably more bitrate than voice, so why care so much about voice bitrates?
One reason is simply the fact that we’re now communicating remotely a lot more. We do that more, and there are also a lot more people communicating online. From everywhere. This means that not all of them are going to be on great networks at all times, and even when they are, others are going to strain these networks with their own traffic. Google calls this “the next billion” – the next billion people joining the internet, which means people with less means and by extension less bandwidth.
The other reason is the fact that we’re growing bigger. More sessions. Bigger sessions. Widely spread. If we can even reduce a fraction of the bitrate, that would reduce the strain on our networks, servers and costs of running services.
I am also guessing that the big video meeting vendors got to learn a few interesting things during the pandemic. One of them is that voice is the most important part of a video call. If you don’t deliver your voice properly, video won’t matter. And for that, you need to make it leaner and meaner than it is today.

How do you make voice compression for an audio codec better?
AI and audio codec generations
I’ll be using machine learning (ML) and artificial intelligence (AI) interchangeably here. These terms have been butchered by marketers so much, that they are now indistinguishable anyway.
Better in the case of audio codecs is going to be a new generation of codecs. In a way, a migration from the old way of doing things (rule engines and heuristics) to our brave new world of machine learning and artificial intelligence.
Machine learning is where the future lies when it comes to most of our algorithms. Especially with the ones that make extensive use today of either rule engines or heuristics – both of which are found in abundance in real time media processing pipelines (=WebRTC). We started seeing this trend seeping into real time communications and WebRTC somewhere in 2018. After the initial hype, we found out the many challenges of adding machine learning. In 2020, it seemed like the path became somewhat clearer: noise suppression and background replacement solutions assisted with AI. For the rest? We understood collectively that we should first squeeze the lemon of optimization before resorting to AI.
It is now time to look at AI in media compression as well. We’ve seen this take place already in baby steps. At Kranky Geek 2019, Shawn Zhong of Agora, explained how AI can be used to improve encoding efficiency:

A year later, NVIDIA introduced Maxine, a platform capable of using AI to “reconstruct” a person. Effectively creating a kind of a compression algorithm.
Research around AI compression is flourishing. There is already an AI specific standards organization called MPAI (Moving Picture, Audio and Data Coding by Artificial Intelligence) – still small, but this may change in the future. And then there’s Mozilla’s Common Voice, an open source, high quality, labeled multi-language dataset for training language related models.

It makes sense then, that audio would be a prime target for AI based compression as well. Here, Microsoft took the first public shot, and Google immediately followed suit.
The Opus spec
To understand where Microsoft Satin and Google Lyra are headed, let’s first review how Opus works:
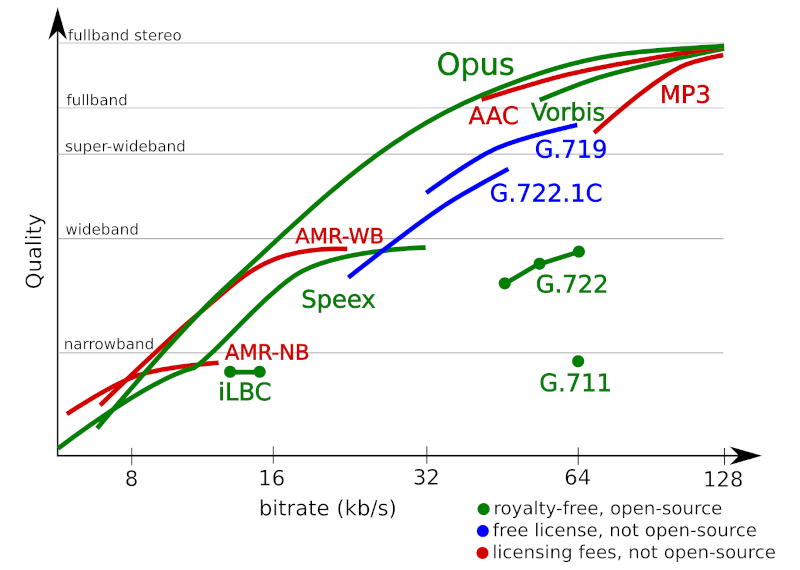
- Opus has a range of 6-510 kbps of compression
- Realistically, for WebRTC, it would be 6-40kbps, and in most cases ~26-30kbps
- It runs the gamut of narrow band up to full-band stereo
- Latency of 26.5ms, making it quite powerful for real time since it adds very little inherent delay of its own
- As mentioned above, for speech, Opus uses a modified SILK implementation. For music it uses CELT, another audio codec. It can use them simultaneously as needed. And interestingly enough, it has a small machine learning model that decides what to use by classifying the audio input as either speech or noise
Now let’s look at what we know so far about the two new audio codecs.
Microsoft Satin
Microsoft Satin is being positioned as an AI-powered audio codec to replace Silk.
Silk is used by Skype and was adopted as the basis for Opus as well. Here’s what Satin can do based on Microsoft’s announcement:
- Super wideband speech starting at a bitrate of 6 kbps
- Full-band stereo music starting at a bitrate of 17 kbps
- Progressively higher quality at higher bitrates
- Provide great audio quality even under high packet loss
- Better redundancy algorithms to provide better protection under burst loss
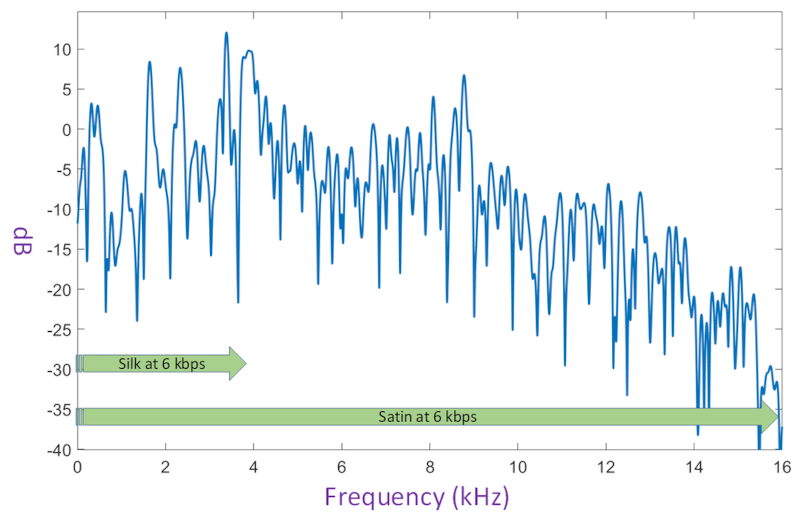
Satin wasn’t presented as a work in progress, but rather as a battle tested codec – Microsoft stated it is already being used by Microsoft Teams and Skype in 2-way calls. Obviously, with plans to extend it to group calls.
Satin is a brand new codec that is being designed to replace Opus altogether.
Google Lyra

Google’s announcement of Lyra came a week after Microsoft’s. In a way, it seemed a bit rushed.
Why rushed? Because of how the announcement is written. It reads similar enough to the Microsoft one but lacks the “currently deployed” paragraph. Instead it has a “currently rolling out” paragraph.
What is Lyra about? Based on Google’s announcement:
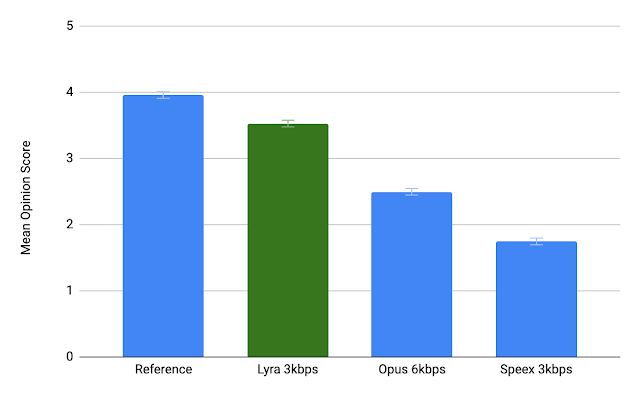
- Very low-bitrate speech codec
- Processing latency of 90ms (on the slow end of the spectrum of real-time voice codecs)
- Designed to operate at 3kbps
- Currently optimized for the 64-bit ARM android platform
Lyra is intended for SPEECH and not for AUDIO. It isn’t a replacement of Opus in any way.
Interestingly, Google believes that coupled with AV1, it can offer decent video conferencing experience at dial-in modem bitrates of 56kbps.
Lyra is being rolled out to Google Duo for very low bandwidth connections scenarios. But that’s about it for the time being.
More recently, Lyra has been open sourced by Google. The reasons for this are varied, especially considering that many of the recent advancements of Google in AI around real time communications weren’t open sourced at all:
- Lyra came after Satin. They will both be fighting it out on being included in WebRTC
- It is superior to Satin (probably) at the very low bitrate of 3kbps, especially considering Satin was designed for 6kbps and above. But it is no match to Satin in higher bitrates, where Satin most probably beats Opus
- Google decided long ago that codecs should be free and open source (see the WebM project). As such, Lyra needs to play by these rules as well. Google might not see a competitive advantage here and would rather have this available across the board
Another thing you can achieve with Lyra is better redundancy for improved resiliency. With its very low bitrate, it is less of a constraint to add redundancy on top of it. You can check out this article on webrtcHacks by Philipp about audio redundancy encoding.
A multi-codec audio future for WebRTC?
At the moment, both Lyra and Satin are nice bedtime stories. You can use them only inside the proprietary implementations of Google and Microsoft. And even then, in most cases you wouldn’t even know that to be the case.
Why was it important then to announce these efforts?
My hunch is that it has to do with standardization and WebRTC.
WebRTC needs some love and attention now in the audio front. For video, we’re going to have AV1, but what do we do about voice?
There are currently two alternatives out there that will make their move soon enough:
- Satin. As a 3rd optional codec in WebRTC. Microsoft will need Google’s approval/help to push this one forward by making it a part of Chrome, otherwise, it won’t gain enough popularity and will be kept proprietary and niche
- Lyra. This codec makes no sense to me as a standalone codec. Adding it to WebRTC “as is” will be quite challenging for developers to make use of. There are a few routes that can be taken here:
- Have it handle wideband and full-band better and in a way competitive to Opus and call it a day. That means competing head-to-head with Satin
- Shove it into Opus. Call it Opus 2.0. Opus already contains SILK and CELT. Why not LYRA as well? Let Opus decide which one to use when and be done with it. Since Lyra is already open sourced, that can be a natural next step…
- Get Google and Microsoft in the same room and see how to put Lyra inside Satin, find a 3rd name for it so no one gets pissed off that the other won the marketing game, and add that new codec into WebRTC
It is too early to say how this will play out. My bet is on more optional audio codecs finding their way into WebRTC – not the boring old ones, but rather the hip new ones. This will make audio codec selection for developers building services a wee bit harder, which isn’t a good thing in the long run. I’d rather see this pushed into Opus – or added as a single codec replacement to Opus. Something that would be easy to pick instead of Opus.
FAQ on Satin and Lyra
No.
While both of these audio codecs operate at low bitrates and are powered by AI they are very different. Lyra is focused on narrowband only while Satin is about operating in super wideband.
Technically – yes.
Microsoft is already using Satin instead of Opus in Microsoft Teams and Skype for 1:1 calls. IT was designed with that goal in mind.
No.
Lyra was designed to work at low bitrates where Opus doesn’t do a good job today. When there’s enough bitrate, Opus offers better audio quality than Lyra.
No.
There are no public plans to add either of these codecs to the WebRTC specification or to browser implementations.
Great and timely perspective, thanks.
Perhaps we will end up sending custom audio codecs over the datachannel like Zoom was/is doing with video? Audio Processors in Javascript, along with Workers and WebAssembly should help.
Some will. For me this is about the unbundling of WebRTC. Something I wrote about last year: https://bloggeek.me/webrtc-unbundling/