Enabling large group video calls in WebRTC is possible, but requires effort. WebRTC CPU consumption requires optimizations and that means making use of a lot of different techniques.

Cramming more users in a single WebRTC call is something I’ve been addressing here for quite some time.
The pandemic around us gave rise to the use and adoption of video conferencing everywhere. Even if this does slow down eventually, we’ve fast forwarded a few years at the very least in how people are going to use this technology.
It all started with a Gallery View
What’s interesting to see is how requirements and feature sets have changed throughout the years when it comes to video conferencing. When I first joined RADVISION, the leading screen layout of a video conference was something like this:

It had multiple names at the time, though today we refer to it mainly as gallery view (because, well… that’s how Zoom calls it).
Somehow, everyone was razor focused on this. Cramming as many people as possible into a single screen. Some of it is because we didn’t know better as an industry at the time. The rest is because video conferencing was a thing done between meeting rooms with large displays.
It also fit rather well with the centralized nature of the MCU, who ruled video conferencing.
Enter Speaker View
At some point in time, we all shifted towards the speaker view (name again, courtesy of Zoom):

There were a few vendors who implemented this, but I think Google Hangouts made it popular. It was the only layout they had available (up until last month), and it was well suited for the SFU technology they used. It also made a lot of sense since Hangouts took place in laptops and desktops and not inside meeting rooms.
With an SFU, we reduce the CPU load of the server by offloading that work to the user devices. At the same time, we increase our demand from the devices.
Hello 2020
Then 2020 happened.

With it came social distancing, quarantines and boredom. For companies this meant that there was a need for townhall meetings for an office, done on a regular interval, just to keep employees engaged. Larger meetings between room meetings because even larger still as everyone started joining them from home.
The context of many calls went from trying to get things done to get connected and providing the shared goals and values that are easier to achieve within the office space. This in turn, got us back to the gallery view.
Oh… and it also made 20+ user meetings a lot more common.
3 reasons why WebRTC is a CPU hog

The starting point is challenging with WebRTC CPU use when it comes to video calling. WebRTC has 3 things going against it at the get go already:
#1 – Video takes up a lot of pixels
1080p@30fps is challenging. And 720p isn’t a walk in the park either.
The amount of pixels to process to encode 1080p?

62 million pixels every second… I can’t count that fast 😂
You need to encode and decode all that, and if you have multiple users in the same call, the number of pixels is going to grow – at least if you’re naive in your solution’s implementation.
What does this all boils down to? WebRTC CPU use will go over the roof, especially as more users are added into that group video call of yours.
#2 – Hardware acceleration isn’t always available
Without hardware acceleration, WebRTC CPU use will be high. Hardware acceleration will alleviate the pain somewhat.
Deciding to use H.264?
- Certain optimizations won’t be available for you in group calling scenarios
- And on devices without direct access to H.264 (some Android devices), you’ll need to use software implementations. It also means dealing with royalty payments on that software implementation
Going with VP8?
- Hardware acceleration for it isn’t available everywhere
- Or more accurately, there’s almost no hardware acceleration available for it
What about VP9?
- Takes up more CPU than H.264 or VP8
- You won’t find it in Safari
- Not many are using it, which is a challenge as well
- Hardware acceleration also a challenge
So all these pixels? Software needs to handle them in many (or all) cases.
#3 – It is general purpose
WebRTC is general purpose. It is a set of APIs in HTML that browsers implement.
These browsers have no clue about your use case, so they are not optimizing for it. They optimize for the greater good of humanity (and for Google’s own use cases when it comes to Chrome).
Implementing a large scale video conference scenario can be done in a lot of different ways. The architecture you pick will greatly affect quality but also the approach you’ll need to take towards optimization. This selection isn’t something that a browser is aware of or even the infrastructure you decide to use if we go with a CPaaS vendor.
And it all boils down to this simple graph:
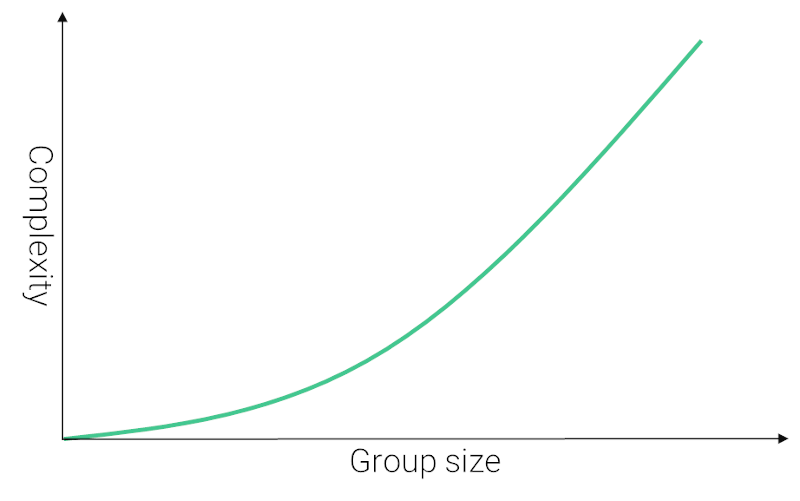
The bigger the meeting size, the more WebRTC CPU becomes a challenge and the harder you need to work to optimize your implementation for it.
Why now?
I’ve been helping out a client last month. He said something interesting –
“We probably had this issue and users complained. Now we have 100x the users, so we hear their complaints a lot more”
We are using video more than ever. It isn’t a “nice to have” kind of a thing – it is the main dish. And as such, we are finding out that WebRTC CPU (which people always complained about) is becoming a real issue. Especially in larger meetings.
Even Google are investing more effort in it than they used to:
3 areas to focus on to improve performance in group video conferences
Here are 3 areas you should invest time in to reduce the CPU use of your group video application:
#1 – Layout vs simulcast
Simulcast is great – if used correctly.
It allows the SFU to send different levels of quality to different users in a conference.
How is that decision made?
- Based on available bandwidth in the downlink towards each participant
- The performance of the device (no need to shove too much down a device’s throat and choke him with more data that it can decode)
- The actual frame resolution of where that video should appear
- How much is that video important for the overall session
Think about it. And see where you can shave off on the bitrates. The lower the total bitrate a device needs to deal with when it has to encode or decode – the lower the CPU use will be.
#2 – Not everyone’s talking
Large conferences have certain dynamics. Not everyone is going to speak his mind. A few will be dominant, some will voice an opinion here and there and the rest will listen in.
Can you mute the participants not speaking? Is there an elegant way for you to do it in your application without sacrificing the user experience?
There are different ways to handle this. Anything from a dominant speaker, through the use of DTX towards automatic muting and unmuting of certain users.
#3 – UI implementation
How you implemented your UI will affect performance.
The way you use CSS, HTML and your JS code will eat up the CPU without even dealing with audio or video processing.
Look at things like the events you process. Try not to run too much logic that ends up changing UI elements every 100 milliseconds of time or less on each media track – you’re going to have a lot of these taking place.
My eBook on the topic is now available
If you are interested in how to further optimize for video conference sizes, then I just published an eBook about it called Optimizing Group Calling in WebRTC. It includes a lot more details and suggestions on the above 3 areas of focus as well as a bunch of other optimization techniques that I am sure you’ll find very useful.

Thank you for the insights. Please advise, is the tech offered by https://www.v-nova.com/v-nova-video-compression-technology/ applicable in a WebRTC based application?
This is proprietary technology and codec as far as I understand. You won’t be able to use it in browsers with WebRTC. You might be able to stitch it into WebRTC for native applications by modifying the baseline WebRTC code, but that won’t work for you in browsers.
Yes/No. To expand on Tsahis answer:
V-Nova sits on top of another codec. If you have a base application with the v-nova codec it will gain its advantages (e.g. decode at 1080p/4K), if not you will decode the base codec at a lower quality e.g. VP8 or H.264 at say 360p.
So a default browser without their codec would still work as that is how their codec has been engineered, but you would not see the optimizations.
If you had control over the users end to end experience such as Electron, iOS, Android, Native desktop (macOS, Windows 10), had a V-Nova license, and appropriately codec binaries, and a dev team which can modify the codecs WebRTC can see it would be a great optimization. The same method applies to all new codecs which are not found as default.