Need WebRTC recording in your application? Check out the various requirements and architectural decisions you’ll have to make when implementing it.

A critical part of many WebRTC applications is the ability to record the session. This might be a requirement for an optional feature or it might be the main focus of your application.
Whatever the reasons, WebRTC recording comes in different shapes and sizes, with quite a few alternatives on how to get it done these days.
What I want to do this time is to review a few of the aspects related to WebRTC recording, making sure that when it is your time to implement, you’ll be able to make better choices in your own detailed requirements and design.
Table of contents
Record-and-upload or upload-and-record

One of the fundamental things you will need to consider is where do you plan the WebRTC recording to take place – on the device or on the server. You can either record the media on the device and then (optionally?) upload it to a server. Or you can upload the media to a server (live in a WebRTC session) and conduct the recording operation itself on the server.
Recording locally uses the MediaRecorder API while uploading uses HTTPS or WebSocket. Recording on the server uses WebRTC peer connection and then whatever media server you use for containerizing the media itself on the server.
Here’s how I’d compare these two alternatives to one another:
| Record-and-upload | Upload-and-record | |
| Technology | MediaRecorder API + HTTPS | WebRTC peer connection |
| Client-side | Some complexity in implementation, and the fact that browsers differ in the formats they support | No changes to client side |
| Server-side | Simple file server | Complexity in recording function |
| Main advantages |
|
|
🔴 When would I record-and-upload?
I would go for client-side recording using MediaRecorder in the following scenarios:
- My sole purpose is to record and I am the only “participant”. Said differently – if I don’t record, there would be no need to send media anywhere
- The users are aware of the importance of the recording and are willing to “sacrifice” a bit of their flexibility for higher production quality
- The recorded stream is more important to me than whatever live interaction I am having – especially if there’s post production editing needed. This usually means podcasts recording and similar use cases
🔴 When would I upload-and-record?
Here’s when I’d use classic WebRTC architectures of upload-and-record:
- I lack any control over the user’s devices and behavior
- Recording is a small feature in a larger service. Think web meetings where recording is optional at the discretion of the users and used a small percentage of the time
- When sessions are long. In general, if the sessions can be longer than an hour, I’d prefer upload-and-record to record-and-upload. No good reason. Just a gut feeling that guides me here
🔴 How about both?
There’s also the option of doing both at the same time – recording and uploading and in parallel to upload-and-record. Confused?
Here’s where you will see this taking place:
- An application that focuses on the creation of recorded podcast-like content that gets edited
- One that is used for interviews where two or more people in different locations have a conversation, so they have to be connected via a media server for the actual conversation to take place
- Since there’s a media server, you can record in the server using the upload-and-record method
- Since you’re going to edit it in post production, you may want to have higher quality media source, so you upload-and-record as well
- You then offer these multiple resulting recordings to your user, to pick and choose what works best for him
Multi stream or single stream recording

If you are recording more than a single media source, let’s say a group of people speaking to each other, then you will have this dilemma to solve:
Will you be using WebRTC recording to get a single mixed stream out of the interaction or multiple streams – one per source or participant?
Assuming you are using an SFU as your media server AND going with the upload-and-record method, then what you have in your hands are separate media streams, each per source. Also, what you need is a kind of an MCU if you plan on recording as a single stream…
For each source you could couple their audio and video into a single media file (say .webm or .mp4), but should you instead mix all of the audio and video sources together into a single stream?
Using such a mixer means spending a lot of CPU and other resources for this process. The illustration below (from my Advanced WebRTC Architecture course) shows how that gets done for two users – you can deduce from there for more media sources:
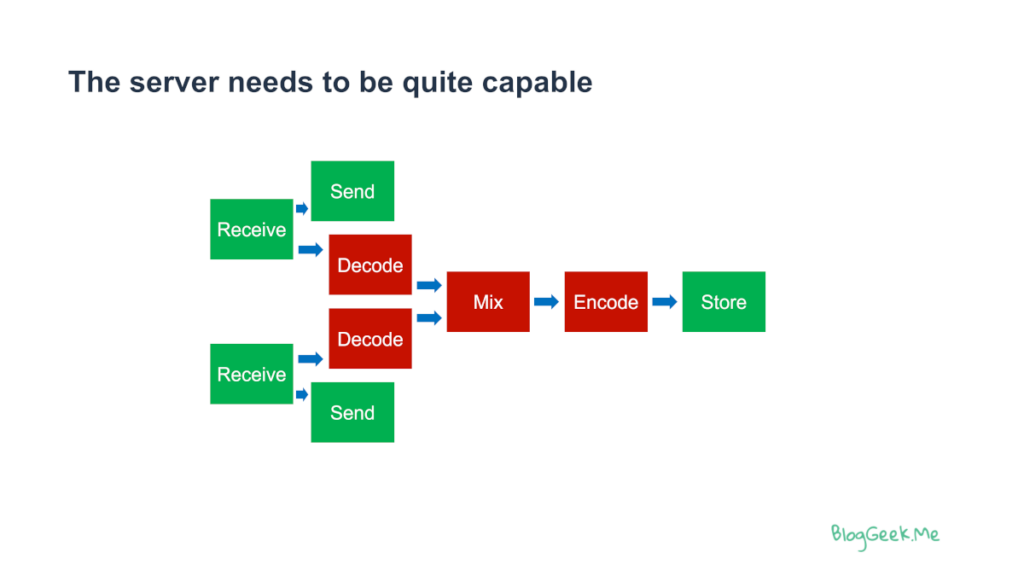
The red blocks are the ones eating up on your CPU budget. Decoding, mixing and encoding are expensive operations, especially when an SFU is designed and implemented to avoid exactly such tasks.
Here’s how these two alternatives compare to each other:
| Multiple streams | Mixed stream | |
| Operation | Save into a media file | Decode, mix and re-encode |
| Resources | Minimal | High on CPU and memory |
| Playback | Customized, or each individual stream separately | Simple |
| Main advantages |
|
|
🔴 When would I use multi stream recording?
Multi stream can be viewed as a step towards mixed stream recording or as a destination of its own. Here’s when I’d pick it:
- When I need to be able to play back more than a single view of the session in different playback sessions
- If the percentage of times recorded sessions get played back is low – say 10% or lower. Why waste the added resources? (here I’d treat it is a step an optional mixed stream “destination”)
- When my customer might want to engage in post production editing. In such a case, giving him more streams with more options would be beneficial
🔴 When would I decide on mixed stream recording?
Mixed recording would be my go-to solution almost always. Usually because of these reasons:
- In most cases, users don’t want to wait or deal with hassles during the playback part
- Even if you choose multi stream for your WebRTC recording, you’ll almost always end up needing to provide also a mixed stream experience
- Playing back multi stream content requires writing a dedicated player (haven’t seen a properly functioning one yet)
🔴 What about mixed stream client side recording?
One thing that I’ve seen once or twice is an attempt to use a device browser to mix the streams for recording purposes. This might be doable, but quality is going to be degraded for both the actual user in the live session as well as in the recorded session.
I’d refrain from taking this route…
Switching or compositing

If you are aiming for a single stream recording, then the next dilemma you need to solve is the one between switching and compositing. Switching is the poor man’s choice, while compositing offers a richer “experience”.
What do I mean by that?
Audio is easy. You always need to mix the sources together. There isn’t much of a choice here.
For video though, the question is mostly what kind of a vantage point do you want to give that future viewer of yours. Switching means we’re going to show one person at a time – the one shouting the loudest. Compositing means we’re going to mix the video streams into a composite layout that shows some or all of the participants in the session.
Google Meet, for example, uses the switching method in its recordings, with a simple composite layout when screen sharing takes place (showing the presenter and his screen side by side, likely because it wasn’t too hard on the mixing CPU).
In a way, switching enables us to “get around” the complexity of single stream creation from multiple video sources:
| Switching | Compositing | |
| Audio | Mix all audio sources | Mix all audio sources |
| Video | Select single video at a time, based on active speaker detection | Pick and combine multiple video streams together |
| Resources | Moderate | High CPU and memory needs |
| Main advantages | Cost effective | More flexible in layouts and understanding of participants and what they visually did during the meeting |
🔴 When would I pick switching?
When the focus is the audio and not the video.
Let’s face it – most meetings are boring anyway. We’re more interested in what is being said in them, and even that can be an exaggeration (one of the reasons why AI is used for creation of meeting summaries and action items in some cases).
The only crux of the matter here, is that implementing switching might take slightly longer than compositing. In order to optimize for machine time in the recording process, we need to first invest in more development time. Bear that in mind.
🔴 When would compositing be my choice?
The moment the video experience is important. Webinars. Live events. Video podcasts.
Media that plan or want to apply post production editing to.
Or simply when the implementation is there and easier to get done.
I must say that in many cases that I’ve been involved with, switching could have been selected. Compositing was picked just because it was thought of as the better/more complete solution. Which begs the question – how can Google Meet get away with switching in 2024? (the answer is simple – it isn’t needed in a lot of use cases).
Rigid layouts or flexible layouts

Assuming you decided on compositing the multiple video streams into a single stream in your WebRTC recording, it is now time to decide on the layout to use.
You can go for a single rigid layout used for all (say tiles or presenter mode). You can go for a few layouts, with the ability to switch from one to the other based on context or some external “intervention”. You can also go for something way more flexible. I guess it all depends on the context of what you’re trying to achieve:
| Single | Rigid | Flexible | |
| Concept | A single layout to rule them all | Have 2, 3 or 7 specific layouts to choose from | Allow virtually any layout your users may wish to use |
| Main advantages |
|
| Users can control everything, so you can offer the best user experience possible |
| Main challenges | What if that single layout isn’t enough for your users? |
|
|
Here’s a good example of how this is done in StreamYard:
StreamYard gives 8 predefined different layouts a host can dynamically choose from, along with the ability to edit a layout or add new ones (the buttons at the bottom right corner of the screen).
🔴 When to aim for rigid layouts?
Here’s when I’ll go with rigid layouts:
- The recording is mostly an after-effect and not the “main course” of the interaction. For the most part, group meetings don’t need flexible layouts (no one cares enough anyway)
- My users aren’t creatives in nature, which brings us to the same point. The WebRTC recording itself is needed, but not for its visual aesthetics – mostly for its content
- When users won’t have the time or energy to pick and choose on their own
Here, make sure to figure out which layouts are best to use and how to automatically make the decision for the users (it might be that whatever the host layout is you record, or based on the current state of the meeting – with screen sharing, without, number of participants, etc).
🔴 When would flexibility be in my menu?
Flexibility will be what I’ll aim for if:
- My users care deeply about the end result (assume it has production value, such as uploading it to YouTube)
- This is a generic platform (CPaaS), and I am not sure who my users are, so some may likely need the extra flexibility
Transcoding pipeline or browser engine

You decided to go for a composite video stream for your WebRTC recording? Great! Now how do you achieve that exactly?
For the most part, I’ve seen vendors pick up one of two approaches here – either build their own proprietary/custom transcoding pipeline – or use a headless browser as their compositor:
| Transcoding pipeline | Browser engine | |
| Underlying technology | Usually ffmpeg or gstreamer | Chrome (and ffmpeg) |
| Concept | Stitch the pipeline on your own from scratch | Add a headless browser in the cloud as a user to the meeting and capture the screen of that browser |
| Resources | High | High, with higher memory requirements (due to Chrome) |
| Main advantages |
|
|
Here I won’t be giving an opinion about which one to use as I am not sure there’s an easy guideline. To make sure I am not leaving you half satisfied here, I am sharing a session Daily did at Kranky Geek in 2022, talking about their native transcoding pipeline:

Since that’s the alternative they took, look at it critically, trying to figure out what their challenges were, to create your own comparison table and making a decision on which path to take.
Live or “offline”

Last but not least, decide if the recording process takes place online or post mortem – live or “offline”.
This is relevant when what you are trying to do is to have a composite single media stream out of the session being recorded. With WebRTC recording, you can decide to start off by just saving the media received by your SFU with a bit of metadata around it, and only later handle the actual compositing:
| Live | “offline” | |
| Concept | Handle recording on demand, as it is taking place. Usually, adding 0-5 seconds of delay | Use job queues to handle the recording process itself, making the recorded media file available for playback minutes or hours after the session ended |
| Main advantages |
|
|
🔴 When to go live?
The simple answer here is when you need it:
- If you plan on streaming the composited media to a live streaming platform
- When all (or most) sessions end up being played back
🔴 When to use “offline”?
Going “offline” has its set of advantages:
- Cost effective – when you’re uncle scrooge
- Commit to compute resources with your cloud vendor and then queue such jobs to get better machine utilization
- You can use spot instances in the cloud to reduce on costs (you may need to retry when they get taken away)
- If the streams aren’t going to be viewed immediately
- Assuming streams are seldomly viewed at all, it might be best to composite them only on demand, with the assumption that storage costs less than compute (depends on how long you need to store these media files)
🔴 How about both?
Here are some suggestions of combinations of these approaches that might work well:
- Mix audio immediately, but wait up with video compositing (it might not be needed at all)
- Use offline, but have the option to bump priority and “go live” based on the session characteristics or when users seem to want to playback the file NOW
Plan your WebRTC recording architecture ahead of time

This has been long. Sorry about that.
Designing your WebRTC recording architecture isn’t simple once you dive into the details. Take the time to think of these requirements and understand the implications of the architecture decisions you make.
Oh, and did I mention there’s a set of courses for WebRTC developers available? Just go check them out at https://webrtccourse.com 😃