It’s the money stupid.
Group calls may and usually do require WebRTC media servers to be deployed.
We all love to hate the model of an MCU (besides those who sell MCUs that is).
There are in general 3 main models of deploying a multiparty video conference:
- Mesh – where each participant sends his media to all other participants
- MCU – where a participant is “speaking” to a central entity who mixes all inputs and sends out a single stream towards each participant
- SFU – where a participant sends his media to a central entity, who routes all incoming media as he sees fit to participants – each one of them receiving usually more than a single stream
I’ve taken the time to use testRTC to show the differences on the network between the 3 multiparty video alternatives on the network.
To sum things up:
- Mesh fails miserably relatively fast. Anything beyond 3 isn’t usable anywhre in a commercial product if you ask me
- MCU seems the best approach when it comes to load on the network
- SFU is asymmetric in nature – similar to how ADSL is (though this can be reduced, just not in Jitsi in the specific scenario I tried)
This being the case, how can I even say that SFU is the winning model for WebRTC?
It all comes down to the cost of operating the service.
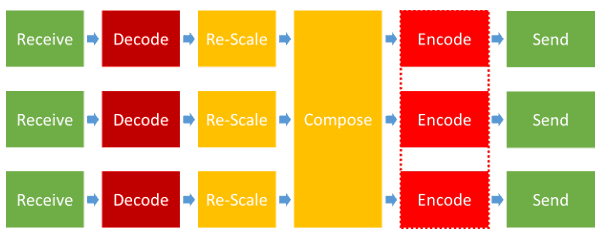
Here’s what an MCU does in front of each participant:
Here’s what an SFU does in front of each participant:
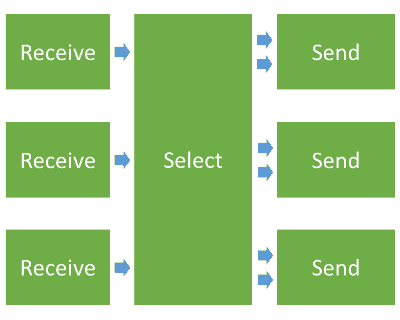
To make things easy for you, I’ve marked with colors varying from green to red the amount of effort it puts on a CPU to deal with it.
The most taxing activity in an MCU is the encoding and decoding of the video. With the current and upcoming changes in video and displays, this isn’t going to lessen any time soon:
- Google just switched to VP9, which takes up more CPU
- 4K displays and cameras are becoming a reality. 8K is being discussed already. This means 4 times the resolutions of full HD
If anything – things are going to get worse here before they get any better.
It is no surprise then that MCUs scale on single machines in the 10’s of ports or low 100’s at best; while SFUs scale on single machines in the 1,000’s of ports or low 10,000’s.
Which brings us to two very important aspects of this:
- Price per port, where an SFU will ALWAYS be lower than MCU – by several factors
- Deployment complexity
The first reason is usually answered by people that if you want quality – you need to pay for it. Which is always true. Until you start reminding yourself that video calling today is priced at zero for the most part.
The second reason isn’t as easy to ignore. If you aim for cloud based services needing to serve multiple customers, your aim is to go to 10,000 or more parallel sessions. Sometimes millions or more. Here would be a good time to remind you that WhatsApp crossed the billion monthly active users and most messaging services become interesting when they cross 100 million monthly active users.
With such numbers, placing 100 times more machines to support an MCU architecture instead of an SFU one is… prohibitive. There are more costs that needs to be factored in, such as power consumption, rack space and higher administration costs.
The end result?
An SFU model is by far the most popular deployment today for WebRTC services.
Does it fit all use cases? No
Will it fit your use case? Maybe
Do customers care? No
Need to pick an open source WebRTC media server framework for your project? Check out this free selection worksheet.
One other thing to bear in mind is that, with an SFU, it’s a relatively easy thing to alter the layout of the web page or mobile app to suit the service provider’s needs. With an MCU, you’re pretty much stuck with whatever screen layout the MCU vendor offers, such as 1 large video + 5 small.
There is no such thing as an “MCU architecture” or an “SFU architecture”. Your system architecture will include one or both building blocks. If you only need a SFU: lucky you!
Philipp is correct, it’s never just one or the other – outside of peer 2 peer one on one call, most use-cases will require a mix of both architecture.
A typical “MCU” focused vendor will decode all incoming streams and merge all decoded streams into one in one encoding pass (one per template times ABR flavors). Then clients will be able to chose between templates (usually there are no more than 3: active speaker, grid, and active + screenshare). It will then also include routing in that it will decide which client should receive which flavor and template. It will be far more efficient on bandwidth consumption (each client only upload once, and download once), and indeed little more taxing on CPU.. here’s why it’s not “by far” more encoding:
A typical “SFU” doesn’t just re-route streams, because if it did, you’ll always end up with poor user experience with many interruptions due to network load. If your conference includes more than 2 participants, in a pure SFU architecture each participant will have to upload once (or more in case there’s ABR) and download several streams (one per participant). Such a scenario will be very taxing on bandwidth and since in most cases upload connections are slow, it’s also impractical to achieve proper ABR with pure SFU. Hence, a more common SFU implementation will also include decoding and encoding, in-order to create the ABR flavors of each participant (which means transcoding pipe per client per flavor), and then it will route the proper flavor to each client. It will still be heavier on bandwidth due to each client receiving multiple streams instead of one. Additionally, the SFU architecture is taxing on the client side rendering side too, and thus requires further specialized applications to be installed on the client side.. as most mobile browsers will crash in the face of having to play multiple video streams concurrently.
In addition, another downside of an SFU is that connecting to devices and applications such as room systems and/or broadcasting to sites like YouTube and Facebook will always require further encoding (usually called “Gateways”) in order to mix all streams into one rtmp/rtsp/webrtc upload.
The exception to above described SFU challenges is ; SVC based SFU. Bringing an important advantage over pure SFU/MCU: It requires less encoding on the server (MCU) for ABR or less upload BW is needed (SFU). In an SVC based SFU each client uploads an “onion of video quality layers” (Read more; http://info.vidyo.com/rs/vidyo/images/WP-Vidyo-SVC-Video-Communications.pdf), the server is then able to decide which layers to send to each client depending on the client, screen size, network connection, etc. This makes the server significantly more efficient, since it’s able to deliver ABR video without having to perform transcoding on the server. Lastly, even with SVC, supporting other devices/sites will require a Gateway for mixing all streams into one (including all browsers that don’t support SVC), and it often requires the use of specialized applications due to SVC being more complex to implement and rather new in browsers.
Another approach is Adaptive SFU
| -> High Quality Encode -> |
receive -> decode ->| | -> Send according to bandwidth
|-> Low Quality Encode -> |
We use this approach at Ant Media Server https://antmedia.io
In addition it supports traditional SFU as well.
Mekya,
Thanks for sharing. I didn’t know this about the AntMedia server.
How to find a particular site is using Muc or SFU or Mesh?
On a 3-way or bigger group call, do the following:
* Open chrome://webrtc-internals
* Check how many incoming and outgoing voice/video channels you see
* 1 incoming and 1 outgoing voice/video channels that is an MCU
* 1 outgoing and many incoming voice/video channels that is an SFU
* many incoming and many outgoing voice/video channels that is Mesh
Not always, but close enough.
A decent MCU will do a central heavy transcoding and prosessing tasks to give each participant a personal layout adapted to its preference/bandwidth, wilst form user side, the CPU load and Bandwidth usage will be the same for a three party conference than for one of 50 participants or more.
As you Tsahi already know, coming form the corporate videoconferencing industry, MCU is the best approach when you hace to take care of end users CPU/Bandwidth.
That was a main issue in the past, and it’s still a problme in several countries where internet connectons are slow and/or there’s not possible to get a powerfull CPU for everyone.
In my opinion, that’s why non corporative platforms have raised popularity home use and when little number of meetings with not many participants. But they showed the other face of that advantage when all the company needed to use it intensively during cuarantine social distancing time, when homeoffice use raised like a rocket.
I see several medium to large meetings (Education is a typical use case) with several problems related to that, were the speakers need to reduce or cancel gallery view of participants to maintain a stable and manageable meetring environment.
Adding the lack of hardware acceleration availability os fome codecs (not H.26X precisely), then the CPU starts to have a heavy duty when encoding camera and shared screen, whilst decoding 25 incoming videos to build the local layout.
MCUs lost their shine.
Almost all modern solutions today use an SFU model for their video delivery. The challenges you speak of exist, but for most make no difference. The cost of an MCU is restrictive, especially considering that it is 10-100 times more expensive to deploy than an SFU.
This doesn’t mean that MCU topologies aren’t good for anything. Just that the number of use cases they are now useful for (for a price/performance perspective) has greatly diminished.